기술 개념 정리
다양한 기술들의 개념을 정리
Architecture
Layered Architecture
애플리케이션을 독립적인 계층으로 분리하여 각 계층이 특정 역할을 수행하는 구조로, 일반적으로 프레젠테이션, 비즈니스, 퍼시스턴스, 데이터베이스 계층으로 구성된다.1
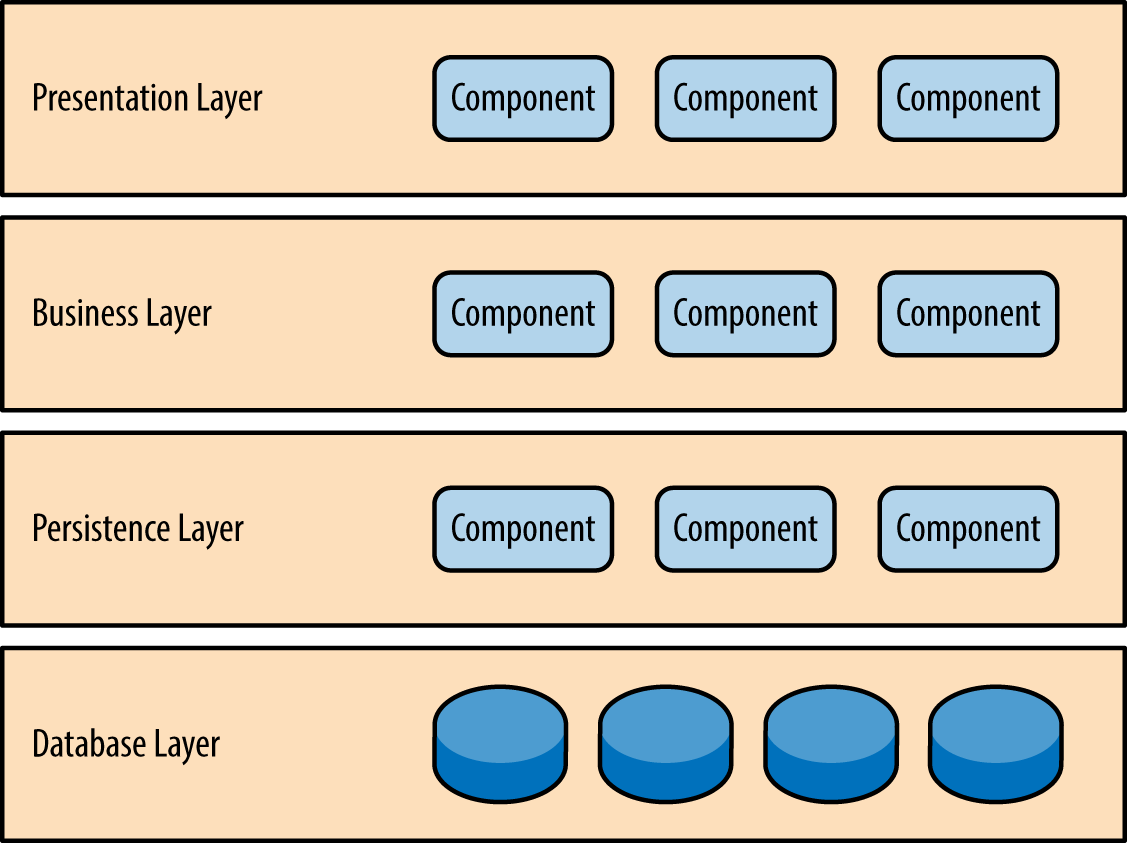 Layered Architecture
Layered Architecture
Monolithic Architecture
애플리케이션의 모든 기능이 하나의 통합된 코드베이스로 구성된 단일 구조로 배포되는 아키텍처이다.
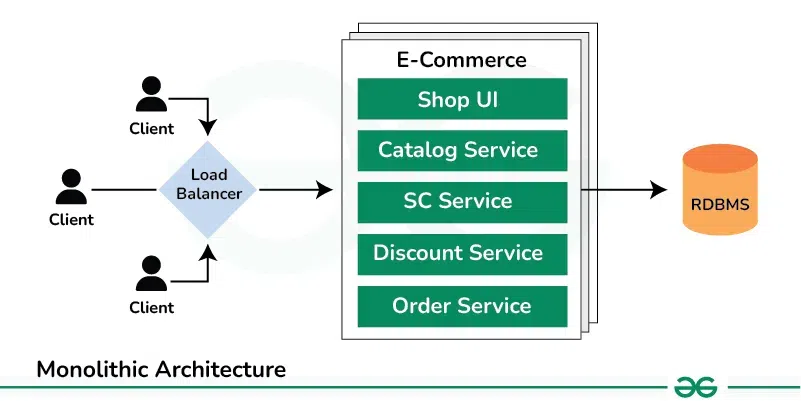 Monolithic Architecture2
Monolithic Architecture2
- 장점
- 개발과 배포가 단순하고, 테스트와 디버깅이 쉬우며, 초기에 빠른 개발이 가능하다.
- 단점
- 확장과 유지보수가 어렵고, 변경이 전체 시스템에 영향을 미쳐 장애 복구와 업데이트에 제약이 생긴다.
Microservice Architecture
애플리케이션을 독립적으로 배포 및 확장할 수 있는 작은 서비스 단위로 분리해 개발하는 아키텍처이다. 애플리케이션이 복잡해지고 팀이 커져 확장성과 독립적인 배포가 필요할 때 적용하는 것이 적절하다.
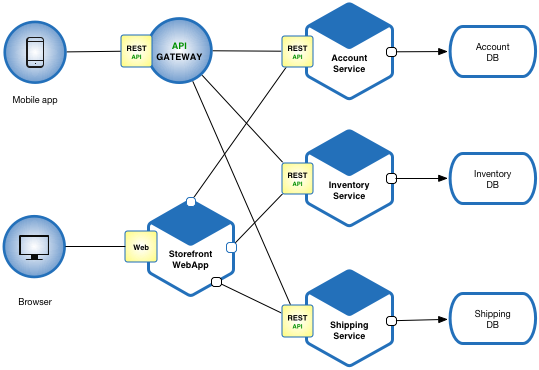 Microservice Architecture3
Microservice Architecture3
- 장점
- 서비스별 독립 배포와 확장이 가능하며, 장애 격리가 용이하고, 다양한 기술 스택을 사용할 수 있다.
- 단점
- 서비스 간 통신이 복잡하고, 모니터링 및 관리가 어려우며, 배포와 테스트가 더 복잡해진다.
MSA 적용 가이드
MSA를 적용하기 위해 필요한 요소들은 다음과 같다.4
- 서비스 분리와 도메인 설계
- 독립적인 서비스가 특정 도메인을 책임지도록 설계한다.
- API 게이트웨이
- 단일 진입점으로 서비스를 통제하며 보안, 인증, 라우팅을 제공한다.
- 독립된 데이터베이스
- 서비스별 독립된 데이터베이스로 데이터 일관성과 독립성을 유지한다.
- 서비스 간 통신
- gRPC, REST API, 메시지 큐(Kafka, RabbitMQ 등)로 동기/비동기 통신 방식을 설정한다.
- 모니터링과 분산 트레이싱
- Prometheus, Grafana, Zipkin으로 성능과 호출 경로를 추적한다.
- 오케스트레이션 도구
- Kubernetes로 컨테이너화된 서비스 배포, 확장 및 관리를 자동화한다.
- CI/CD 파이프라인
- Jenkins, Github Actions 등으로 지속적 통합과 배포를 설정하여 신속한 배포를 지원한다.
- 중앙 로그 관리
- ELK Stack(Elasticsearch, Logstash, Kibana)으로 서비스별 로그를 수집하고 중앙에서 관리한다.
Hexagonal Architecture
애플리케이션의 핵심 비즈니스 로직과 외부 시스템(데이터베이스, API 등) 간 의존성을 포트와 어댑터로 분리하여, 핵심 로직이 외부 환경에 영향을 받지 않도록 하는 구조이다.
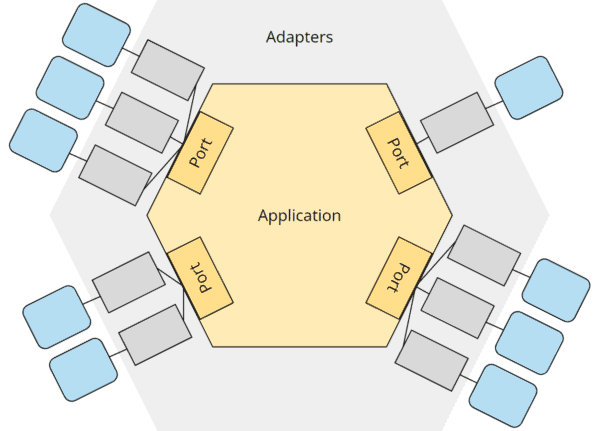 비즈니스 로직, 포트, 어댑터, 외부 컴포넌트로 구성된 Hexagonal Architecture5
비즈니스 로직, 포트, 어댑터, 외부 컴포넌트로 구성된 Hexagonal Architecture5
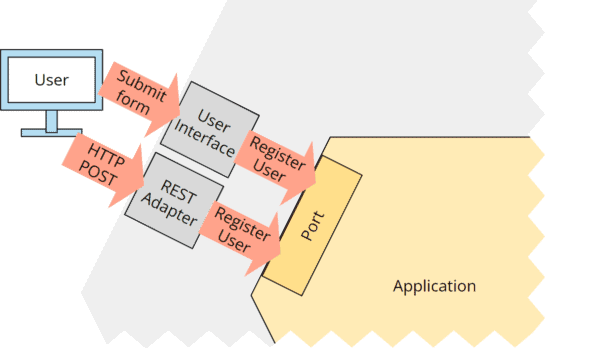 UI와 사용자 어댑터를 통해 Port로 요청 전달5
UI와 사용자 어댑터를 통해 Port로 요청 전달5
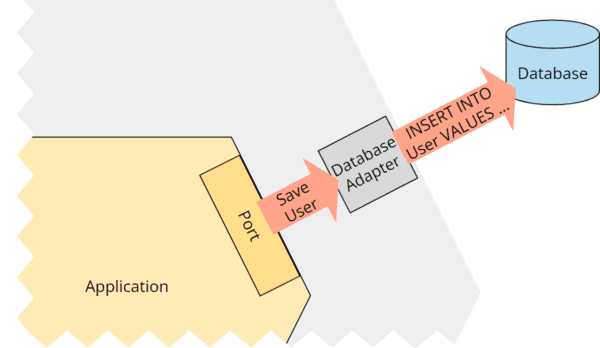 Port를 통해 데이터베이스로 요청 전달5
Port를 통해 데이터베이스로 요청 전달5
- 장점
- 비즈니스 로직과 외부 의존성 분리로 테스트와 유지보수가 용이하며, 유연한 구조로 확장성과 모듈성이 높음
- 단점
- 초기 설계와 구현이 복잡할 수 있고, 작은 프로젝트에서는 오버엔지니어링이 될 가능성이 있음
CQRS (Command Query Responsibility Segregation)
명령과 조회를 분리하여 각 작업에 최적화된 데이터 모델을 사용하는 아키텍처 패턴이다. 복잡한 비즈니스 로직과 읽기-쓰기 성능 요구가 높은 애플리케이션에 적합하다.
- 장점
- 성능과 확장성이 향상되고, 복잡한 비즈니스 로직을 효과적으로 처리할 수 있다.
- 단점
- 구현 복잡도가 높아지고, 데이터 일관성 관리가 어려워질 수 있다.
Event Sourcing
상태 변경을 이벤트로 저장하여 시스템 상태를 재구성하는 아키텍처 패턴이다. 상태 변경 기록이 중요하고 과거 데이터 복구나 감사 추적이 필요한 애플리케이션에 적합하다.
- 장점
- 모든 상태 변경 기록을 보존해 데이터 복구와 추적이 용이하며, 과거 상태 재구성이 가능하다.
- 단점
- 구현 복잡도가 높고, 이벤트 저장소 관리와 일관성 유지가 어려울 수 있다.
REST (Representational State Transfer)
분산 하이퍼미디어 시스템을 위한 아키텍처 스타일이다. HTTP 프로토콜을 기반으로 자원을 CRUD 방식으로 접근하며, URL과 HTTP 메서드(GET, POST, PUT, DELETE 등)를 활용해 클라이언트와 서버 간 통신을 간편하게 한다.6
REST API 설계 원칙
- 클라이언트-서버 구조 : 클라이언트와 서버를 분리하여 독립적 개발과 확장성을 보장한다.
- 무상태성 : 각 요청은 독립적이며, 서버는 요청 간 상태를 저장하지 않는다.
- 캐시 가능성 : 응답은 캐시 가능해야 하며, 이를 통해 성능을 향상시킨다.
- 계층 구조 : 계층 구조로 설계하여 상호 작용하는 계층을 넘는 접근을 막는다.
- 일관된 인터페이스 : URI를 통해 자원을 명확히 식별하고, 표준 HTTP 메서드를 사용해 일관성 있는 인터페이스를 유지한다.
- 코드 온 디멘드 (선택) : 클라이언트가 스크립트 코드를 다운로드 받아서 확장할 수 있다.
REST API 설계 시 중요 요소
클라이언트와 서버 간의 원활한 통신을 위해서는 API 설계 시 일관성과 명확성이 중요하다. 일관성과 명확성이 중요한 이유는 다음과 같다.
- 사용 용이성
- API를 사용하는 개발자가 쉽게 이해하고 예측 가능하게 사용하도록 도와준다.
- 예측 가능한 설계는 코드 작성과 디버깅을 단순화하여, 개발 속도를 높이고 오류를 줄인다.
- 유지보수성과 확장성
- 새 기능을 추가하거나 수정할 때 전체 시스템의 일관성을 유지할 수 있다.
- 유지보수가 용이해지고 확장성이 높아진다.
- 에러 감소
- 일관성 있고 명확한 구조는 API 사용 시 발생할 수 있는 실수를 줄인다.
- 개발자들이 더 빠르고 효율적으로 문제를 해결할 수 있다.
DB
ACID
데이터베이스 트랜잭션의 신뢰성을 보장하는 속성으로, 원자성(Atomicity), 일관성(Consistency), 고립성(Isolation), 지속성(Durability)을 의미한다.
- 원자성(Atomicity) : 트랜잭션은 완전히 수행되거나 전혀 수행되지 않아야 한다.
- 일관성(Consistency) : 트랜잭션 전후에 데이터베이스에는 항상 일관된 상태여야 한다.
- 고립성(Isolation) : 각 트랜잭션은 독립적으로 실행되어야 하며, 다른 트랜잭션의 영향을 받지 않아야 한다.
- 지속성(Durability) : 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로 저장되어야 한다.
RDBMS (Relational Database Management System)
데이터를 테이블 형태로 저장하고 관계를 통해 관리하는 데이터베이스 관리 시스템
예시로는 Oracle, MySQL, PostgreSQL 등이 있다. Oracle은 상용으로 기능이 풍부하고 안정적이며, MySQL은 가볍고 빠른 오픈소스이고, PostgreSQL은 확장성과 표준 준수성이 높은 강력한 오픈소스이다.
Oracle
- 장점
- 강력한 보안, 높은 확장성, 대규모 엔터프라이즈 기능 지원
- 단점
- 높은 라이선스 비용과 복잡한 관리 필요
MySQL
- 장점
- 빠르고 가벼우며, 웹 애플리케이션에 적합하고 오픈 소스
- 단점
- 복잡한 쿼리와 대규모 데이터 처리 기능이 제한적
PostgreSQL
- 장점
- ACID 준수, 고급 쿼리와 데이터 무결성 지원, 오픈 소스
- 단점
- 관리가 다소 복잡하고, 특정 상황(단순 조회나 작은 데이터 세트에 대한 읽기)에서 MySQL보다 느릴 수 있음
PostgreSQL과 MySQL 중 하나를 선택하는 방법7
PostgreSQL은 쓰기 작업이 빈번하고 쿼리가 복잡한 엔터프라이즈급 애플리케이션에 더 적합하다. 하지만 읽기 횟수가 많고 데이터 업데이트가 자주 이루어지지 않는다면 MySQL이 적합하다.
Index
데이터베이스에서 검색 속도를 높이기 위해 특정 열에 대한 정렬된 데이터를 미리 저장한 구조로, 책의 목차처럼 데이터를 빠르게 찾도록 도와준다.
- 장점
- 검색 성능이 크게 향상되어 조회 속도가 빨라짐
- 단점
- 추가 저장 공간 필요, 인덱스가 많은 경우 삽입, 업데이트 시 성능 저하
PostgreSQL은 기본적으로 B-트리 인덱스를 사용하며, 이 외에도 GIN, GiST, Hash, SP-GiST 등의 다양한 인덱스 구조를 지원하여 데이터 타입과 쿼리 유형에 맞게 최적의 성능을 제공한다.
- B-트리 인덱스
- 균형 잡힌 트리 구조로, 데이터가 정렬된 상태로 저장되어 있어 검색, 삽입, 삭제 작업을 효율적으로 수행할 수 있는 인덱스 구조이다.
Isolation Levels
하나의 트랜잭션이 실행되는 동안 다른 트랜잭션의 영향으로부터 얼마나 격리(Isolation)되어 있는지를 정의하는 기준이다. 높은 격리 수준일수록 트랜잭션 간의 간섭이 적어지지만, 그만큼 성능에 부담을 줄 수 있다.
- READ UNCOMMITTED (읽기 미완료)
- 가장 낮은 격리 수준, 트랜잭션이 아직 커밋되지 않은 다른 트랜잭션의 데이터를 읽을 수 있다.
(발생 가능 : 더티 리드, 비반복 가능한 리드, 팬텀 리드) - READ COMMITTED (읽기 완료)
- 기본 격리 수준, 트랜잭션이 커밋된 데이터만 읽을 수 있다. (발생 가능 : 비반복 가능한 리드, 팬텀 리드)
- REPEATABLE READ (반복 가능한 읽기)
- 트랜잭션이 시작된 시점의 데이터를 지속적으로 읽을 수 있다. (발생 가능 : 팬텀 리드)
- SERIALIZABLE (직렬화)
- 가장 높은 격리 수준, 트랜잭션이 완전히 직렬화되어 실행되며 동시에 실행되는 트랜잭션이 서로 간섭하지 않는다.
(발생 가능 : X, 모든 트랜잭션이 직렬적으로 실행)
In-memory Database
데이터를 디스크가 아닌 메모리에 저장하여 매우 빠른 읽기 및 쓰기 속도를 제공하는 데이터베이스이다. 대표적인 예시로는 Redis, Memcached 가 있다.
Redis
오픈 소스 인메모리 데이터 구조 저장소로, 데이터베이스, 캐시, 메시지 브로커 등 다양한 용도로 활용된다. 데이터를 메모리에 저장하여 매우 빠른 성능을 제공하며, 문자열, 리스트, 해시, 셋, 정렬된 셋 등 다양한 데이터 구조를 지원한다. 또한, 복제, 클러스터링, 지속성 옵션 등을 통해 고가용성과 확장성을 제공한다.8
- 장점
- 고속 성능, 다양한 데이터 구조 지원, 영속성 옵션, 복제 및 클러스터링
- 단점
- 메모리 의존성, 복잡한 쿼리 제한, 단일 스레드 처리
Memcached
고성능의 분산 메모리 객체 캐시 시스템으로, 주로 동적 웹 애플리케이션의 데이터베이스 부하를 줄이고 응답 속도를 향상시키기 위해 사용된다. 데이터를 메모리에 저장하여 빠른 읽기 및 쓰기를 지원하며, 키-값(key-value) 구조로 데이터를 관리한다.9
- 장점
- 고속 성능, 단순한 설계, 확장성, 낮은 메모리 오버헤드
- 단점
- 데이터 영속성 부족, 제한된 데이터 구조, 데이터 일관성 관리 필요
Redis와 Memcached 중 하나를 선택하는 방법
- 데이터 구조 지원
- Redis : 문자열, 리스트, 해시, 셋, 정렬된 셋 등 다양한 데이터 구조를 지원하여 복잡한 데이터 처리가 가능
- Memcached : 단순한 키-값 저장소로, 문자열 형태의 데이터만 저장 가능
- 데이터 영속성
- Redis : RDB와 AOF 방식을 통해 영속성 보장
- Memcached : 서버 재시작 시 데이터 소실
- 성능 및 확장성
- Redis : 단일 스레드로 동작하지만, 복제와 클러스터링을 통해 확장성과 고가용성 제공
- Memcached : 멀티스레드를 지원하여 멀티코어 시스템에서 효율적으로 동작하며, 분산 아키텍처로 확장성이 뛰어남
- 사용 사례
- Redis : 세션 관리, 실시간 분석, 메시지 브로커 등 복잡한 데이터 구조와 영속성이 필요한 경우 적합
- Memcached : 단순한 캐싱이 필요하고 데이터 영속성이 중요하지 않은 경우에 적합
NoSQL
RDBMS의 정형화된 스키마 구조를 벗어나, 다양한 데이터 모델(문서, 키-값, 컬럼, 그래프 등)을 지원하고 수평 확장(scale-out)에 유리한 비관계형 데이터베이스를 의미한다. 이를 통해 변화하는 데이터 스키마에 빠르게 대응하고, 대규모 데이터 처리 및 높은 성능 요구사항을 충족시킬 수 있다.
NoSQL은 다음과 같은 특징을 갖는다.
- 스키마 유연성 : 엄격한 스키마를 요구하지 않거나 최소화하여, 변화하는 비정형 데이터 구조에 민첩하게 대응할 수 있다.
- 수평 확장성 : 서버 노드를 추가하는 것만으로 처리 능력을 향상시킬 수 있다.
- 다양한 데이터 모델
- 키-값(Key-Value) : 단순한 키-값 쌍으로 데이터를 관리하며, 매우 빠른 조회 성능을 제공 (ex. Redis, Riak)
- 문서(Document) DB : JSON, BSON 등의 문서 형식으로 저장하여 복잡한 구조를 유연하게 표현 (ex. MongoDB, CounchDB)
- 컬럼(Column-family) DB : 컬럼 기반으로 대량 데이터 분석에 최적화된 구조 (ex. Cassandra, HBase)
- 그래프(Graph) DB : 노드와 엣지로 데이터를 표현해 관계 중심 분석에 유용 (ex. Neo4j)
- CAP 이론 고려 : NoSQL은 일관성(Consistency), 가용성(Availability), 파티션 내성(Partition Tolerance)의 세 가지 속성 중 두 가지를 최적으로 만족하고 하나를 어느 정도 희생하는 경우가 많다.
RDBMS vs NoSQL
안정적인 트랜잭션 처리와 정형화된 데이터 관리가 필요하면 RDBMS, 대규모 확작성과 유연한 스키미가 필수적이면 NoSQL을 선택하는 것이 좋다.
MongoDB
문서(Document) 지향 데이터베이스로, JSON(BSON) 형태의 문서 단위로 데이터를 저장하고 처리한다. 이를 통해 스키마 유연성과 확장성을 높여 대규모 웹 애플리케이션, 실시간 분석 등에 적합한 고성능 비관계형(NoSQL) 데이터베이스이다.
이 문서들은 키-값 쌍으로 구성되며, 테이블이나 행이 아닌 컬렉션(Collection)에 저장된다. 스키마가 유동적이거나 데이터 구조가 자주 변하는 환경에서 특히 유연하고 편리하다.
MongoDB는 다음과 같은 특징을 갖는다.
- 유연한 스키마(Schema-less) : 사전 정의 없이 문서 형태로 데이터를 저장할 수 있다. 이를 통해 개발 초기 단계에서의 스키마 설계 부담을 줄이고, 데이터 구조 변경이 빈번한 애플리케이션에서도 유연한 대응이 가능하다.
- 고성능 읽기/쓰기 및 수평 확장성(Scalability) : 샤딩(Sharding)을 통해 수평적 확장(Scale-out)이 용이하다. 또한 인덱싱, 메모리 내 처리, 애그리게이션 프레임워크를 활용한 고성능 쿼리 처리를 지원한다.
- 풍부한 쿼리 및 집계 기능 : 복잡한 쿼리, 정렬, 조인-like 연산, 강력한 집계 파이프라인을 지원한다.
- 다양한 언어 및 플랫폼 지원 : 다양한 프로그래밍 언어와 프레임워크에서 쉽게 사용할 수 있는 공식 드라이버와 풍부한 생태계를 갖추고 있다.
- 사용 사례
- 빈번한 스키마 변화가 필요한 웹 애플리케이션
- JSON 기반 REST API 백엔드
- 실시간 분석, 로그 관리, 세션 관리
- 반정형 또는 비정형 데이터 처리
Language
Kotlin
간결하고 안전한 구문을 제공하는 JVM 기반 프로그래밍 언어로, Java와의 호환성이 뛰어나 Android 개발 및 서버 개발에서 널리 사용된다. 널 안정성(null safety)과 람다 표현식, 확장 함수 등의 기능을 제공해 코드가 짧고 오류 가능성이 적어 간결하고 안전하다.10
Coroutine
프로그램 내에서 비동기 작업을 효율적으로 처리하기 위한 경량 스레드이다. 코루틴을 사용하면 함수 실행을 일시 중지하고 필요한 시점에 재개할 수 있어, 복잡한 비동기 로직을 간결하고 직관적으로 작성할 수 있다.
Kotlin은 suspend 함수를 사용해 비동기 작업을 일시 중지하고 재개할 수 있으며, 다음과 같은 원리로 동작한다.
- suspend 키워드 : 코루틴 내의 일시 중단 가능한 함수를 정의. suspend 함수는 실행 도중 다른 코루틴에 제어권을 넘겨주거나, 스레드를 차단하지 않고 일시 중단할 수 있다.
- Coroutine Dispatcher : 특정 코루틴의 실행을 관리하며, 디스패처를 통해 어떤 스레드에서 작업이 실행될지를 결정
- 일시 중지와 재개 : suspend 함수는 실행 중 비동기 작업이 끝날 때까지 일시 중지(suspend) 될 수 있고, 이후에 자동으로 재개(resume) 된다. 이를 통해 스레드를 차단하지 않고도 기다림을 처리한다.
- Continuation : 일시 중지된 지점에서 다시 시작할 때 Continuation 객체를 사용하여 작업을 재개
Kotlin과 Java의 차이점
- 문법적 간결성
- Kotlin : 불필요한 코드 작성을 줄여 가독성을 높여준다.
data class를 선언할 때 자동으로equals(),hashCode(),toString()메서드가 생성된다. - Java : 명시적으로 모든 메서드와 필드를 작성해야 하므로 코드가 장황해질 수 있다.
- Kotlin : 불필요한 코드 작성을 줄여 가독성을 높여준다.
- Null 안정성
- Kotlin : NullPointerException을 방지하기 위해 컴파일 시점에 null 가능성을 검사한다.
- Java : 런타임 시에만 null 검사가 이루어져 NullPointerException이 발생할 수 있다.
- 함수형 프로그래밍 지원
- Kotlin : 람다 표현식, 고차 함수 등 함수형 프로그래밍 기능을 기본적으로 지원한다.
- Java : Java 8부터 람다 표현식을 도입했지만, 함수형 프로그래밍 지원이 제한적이다.
- 확장 함수
- Kotlin : 기존 클래스에 새로운 함수를 추가할 수 있는 확장 함수를 지원한다.
- Java : 이러한 기능을 지원하지 않으며, 상속이나 유틸리티 클래스를 통해 구현해야 한다.
- 코루틴 지원
- Kotlin : 비동기 프로그래밍을 위한 코루틴을 기본적으로 지원한다.
- Java : 비동기 처리를 위해 별도의 라이브러리나 스레드 관리를 해야 한다.
Java
객체 지향 프로그래밍 언어로, 플랫폼 독립성, 강력한 라이브러리, 안정성과 확장성 덕분에 웹, 모바일, 엔터프라이즈 애플리케이션에서 널리 사용된다.
JVM (Java Virtual Machine)
자바 애플리케이션을 운영체제와 무관하게 실행할 수 있도록 바이트코드를 해석하고 실행하는 가상 머신으로, 메모리 관리와 가비지 컬렉션 등의 기능을 제공한다.
메모리 관리
JVM은 여러 영역으로 나뉘어 각기 다른 역할을 담당한다.
- 메소드 영역 (Method Area)
- 클래스, 메소드, 인터페이스 등의 메타데이터 정보를 저장하는 영역으로, 모든 스레드가 공유한다.
- 클래스가 로드될 때 생성되며, 주로 정적 변수와 메소드 정보를 보관한다.
- 힙 영역 (Heap Area)
- JVM에서 가장 큰 메모리 영역으로, 객체와 인스턴스 변수가 저장되는 공간이다.
- 모든 스레드가 공유하며, 가비지 컬렉터(Garbage Collector)가 더 이상 참조되지 않는 객체를 자동으로 제거하여 메모리 누수를 방지한다.
- 스택 영역 (Stack Area)
- 메서드 호출 시 생성되는 지역 변수, 매개변수, 리턴 주소 등이 저장된다.
- 스레드별로 독립적인 공간이 제공되며, 메서드가 호출될 때마다 스택 프레임이 생성되고, 메서드가 종료되면 해당 프레임이 제거된다.
- PC 레지스터 (Program Counter Register)
- 각 스레드마다 생성되며 현재 실행 중인 명령어의 주소를 저장한다.
- 스레드가 작업을 수행할 때 다음 실행 위치를 지정하는 역할을 한다.
- 네이티브 메소드 스택 (Native Method Stack)
- Java 외의 네이티브 코드를 실행하는 공간으로, C/C++ 등 네이티브 메소드를 호출할 때 사용된다.
가비지 컬렉션 (Garbage Collection)
- JVM은 힙 영역의 메모리를 효율적으로 관리하기 위해 가비지 컬렉터를 사용하여 참조되지 않는 객체를 제거한다.
- 주로 ‘마크 앤 스위프(Mark and Sweep)’ 방식으로 작동하며, 세대별(Young Generation, Old Generation) 로 구분하여 객체의 생존 기간에 따라 메모리를 효율적으로 청소한다.
- Mark and Sweep : 힙 영역의 모든 객체를 순회하면서 참조되지 않는 객체를 제거하여 메모리를 회수
- Young Generation : 새로 생성된 객체들을 저장하는 공간. Minor GC가 빈번하게 발생하며 빠르게 처리
- Old Generation : 수명이 긴 객체들을 저장하는 공간. GC 빈도가 낮지만 Major GC(Full GC)가 발생하여 처리 시간이 오래 걸림
LTS(Long-Term-Support) Versions
Java 8
- 람다 표현식
1
2
3
4
5
6
7
8
9
10
11
12
// 이전 방식
Runnable r1 = new Runnable() {
@Override
public void run() {
System.out.println("Hello, World!");
}
};
// 람다 표현식 사용
Runnable r2 = () -> System.out.println("Hello, World!");
- 스트림 API
1
2
3
4
5
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.stream()
.filter(name -> name.length() > 3)
.forEach(System.out::println);
- 함수형 인터페이스
1
2
3
4
Predicate<Integer> isEven = (n) -> n % 2 == 0;
System.out.println(isEven.test(4)); // 출력: true
System.out.println(isEven.test(7)); // 출력: false
- 인터페이스의 기본 메서드와 정적 메서드
1
2
3
4
5
6
7
interface MyInterface {
void existingMethod();
default void newDefaultMethod() {
System.out.println("This is a default method.");
}
}
- 날짜와 시간 API (java.time 패키지)
1
2
3
LocalDate today = LocalDate.now();
LocalDate nextWeek = today.plusWeeks(1);
System.out.println(nextWeek); // 출력: 현재 날짜로부터 1주일 후의 날짜
- 옵셔널 클래스
1
2
Optional<String> optional = Optional.ofNullable("Hello");
optional.ifPresent(System.out::println); // 출력: Hello
- 병렬 배열 정렬
1
2
3
4
5
6
7
int[] numbers = {5, 3, 8, 1, 2, 7, 4, 6};
// 병렬 정렬
Arrays.parallelSort(numbers);
System.out.println("정렬된 배열: " + Arrays.toString(numbers));
// 출력: 정렬된 배열: [1, 2, 3, 4, 5, 6, 7, 8]
Java 11
- var 키워드를 사용한 지역 변수 타입 추론
1
2
var list = List.of("A", "B", "C");
list.forEach((var item) -> System.out.println(item));
- 표준 HTTP/2 클라이언트 API
1
2
3
4
5
6
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://example.com"))
.build();
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
- String 클래스의 새로운 메서드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
String empty = " ";
System.out.println(empty.isBlank()); // true
String text = " Hello, Java 11! ";
System.out.println(text.strip()); // "Hello, Java 11!"
System.out.println("Repeat: ".repeat(3)); // "Repeat: Repeat: Repeat: "
String multiline = "Line1\nLine2\nLine3";
multiline.lines().forEach(System.out::println);
// 출력:
// Line1
// Line2
// Line3
- 파일 읽기 및 쓰기 간소화
1
2
3
Path path = Files.writeString(Files.createTempFile("demo", ".txt"), "Hello, Java 11!");
String content = Files.readString(path);
System.out.println(content); // 출력: Hello, Java 11!
- 직접 실행 지원
1
$ java HelloWorld.java
Java 17
- 패턴 매칭
1
2
3
4
Object obj = "Hello, Java 17!";
if (obj instanceof String s) {
System.out.println(s.toUpperCase());
}
- 명확한 상속 구조를 위한 Sealed 클래스
1
2
3
public sealed class Shape permits Circle, Square {}
public final class Circle extends Shape {}
public final class Square extends Shape {}
- 레코드 클래스
1
2
3
4
5
public record Point(int x, int y) { }
Point p = new Point(10, 20);
System.out.println(p.x() + ", " + p.y()); // 10, 20
System.out.println(p); // Point[x=10, y=20]
- 강력한 캡슐화 : 내부 JDK 클래스를 외부에서 접근하지 못하도도록 캡슐화를 강화하여 보안과 안정성을 높임
Java 21
- 가상 스레드 : 경량화된 스레드로 동시성 프로그래밍의 성능과 확장성을 향상시킨다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 가상 스레드 시작
Thread.startVirtualThread(() -> {
System.out.println("가상 스레드에서 실행 중!");
});
// 가상 스레드 풀 사용
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 10; i++) {
int taskNumber = i;
executor.submit(() -> {
System.out.println("작업 " + taskNumber + "이(가) 가상 스레드에서 실행 중.");
});
}
} // executor는 자동으로 종료됩니다.
- 구조적 동시성 (preview) : 동시 작업의 관리를 단순화하는 새로운 API를 제공
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import java.util.concurrent.*;
public class StructuredConcurrencyExample {
public static void main(String[] args) {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Future<String> user = scope.fork(() -> fetchUser());
Future<Integer> order = scope.fork(() -> fetchOrder());
scope.join(); // 모든 태스크가 완료될 때까지 대기
scope.throwIfFailed(); // 예외 발생 시 전파
// 결과 사용
System.out.println("사용자: " + user.resultNow());
System.out.println("주문: " + order.resultNow());
} catch (Exception e) {
e.printStackTrace();
}
}
static String fetchUser() throws InterruptedException {
Thread.sleep(1000); // 시뮬레이션을 위한 지연
return "홍길동";
}
static int fetchOrder() throws InterruptedException {
Thread.sleep(500);
return 42;
}
}
- 레코드 패턴 : 객체 분리를 위한 매턴 매칭 기능 강화
1
2
3
4
5
6
7
8
9
10
11
public record Point(int x, int y) {}
public class RecordPatternExample {
public static void main(String[] args) {
Object obj = new Point(10, 20);
if (obj instanceof Point(int x, int y)) {
System.out.println("x: " + x + ", y: " + y);
}
}
}
- Switch 패턴 매칭 : switch 문에서 패턴 매칭을 활용 가능
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class PatternMatchingSwitchExample {
public static void main(String[] args) {
Object obj = 123;
String result = switch (obj) {
case null -> "null 값입니다.";
case String s -> "문자열: " + s;
case Integer i && i > 100 -> "100보다 큰 정수: " + i;
case Integer i -> "정수: " + i;
default -> "알 수 없는 타입입니다.";
};
System.out.println(result);
}
}
- 시퀀스 컬렉션 : 일관된 순서를 가진 컬렉션을 위한 새로운 인터페이스 추가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import java.util.*;
public class SequencedCollectionExample {
public static void main(String[] args) {
SequencedSet<String> sequencedSet = new LinkedHashSet<>();
sequencedSet.add("첫번째");
sequencedSet.add("두번째");
sequencedSet.add("세번째");
for (String s : sequencedSet) {
System.out.println(s);
}
// 결과:
// 첫번째
// 두번째
// 세번째
}
}
- String 템플릿 (preview) : 문자열 내에서 변수를 간편하게 삽입할 수 있는 기능 제공
1
2
3
4
5
6
7
8
9
10
11
12
// 컴파일러 옵션에 --enable-preview 필요
public class StringTemplateExample {
public static void main(String[] args) {
int x = 10;
int y = 20;
String result = STR."좌표는 ({x}, {y}) 입니다.";
System.out.println(result);
// 출력: 좌표는 (10, 20) 입니다.
}
}
- Foreign Function & Memory API : JVM 외부의 메모리와 함수를 안전하게 사용할 수 있는 API 제공
- Vector API 개선 : SIMD 연산을 위한 벡터 API가 강화되어 고성능 계산이 가능
TypeScript
JavaScript에 정적 타입 검사와 객체지향 기능을 추가하여 코드 안정성과 가독성을 높여주는 프로그래밍 언어이다.11
JavaScript
웹 페이지에 동적인 기능을 추가하기 위한 프로그래밍 언어로, 브라우저와 서버에서 모두 실행 가능하며, 인터랙티브한 사용자 경험을 제공한다.12
Code Quality
OOP (Object-Oriented Programming)
프로그램을 객체로 구성하고, 이 객체들이 상호작용하여 작업을 수행하는 프로그래밍 패러다임이다. 캡슐화, 상속, 추상화, 다형성의 네 가지 특징을 기반으로 하며, 코드 재사용성과 유지보수성을 높이고, 복잡한 문제를 객체 단위로 쉽게 관리할 수 있도록 한다.
- 캡슐화 (Encapsulation)
- 외부로부터 데이터에 직접 접근하지 못하도록 제한하여 데이터 무결성을 보호하는 원칙
- 상속 (Inheritance)
- 기존 클래스의 속성과 메서드를 새로운 클래스가 물려받아 코드 재사용성을 높이고, 계층 구조를 통해 유사한 클래스들을 조직화할 수 있게 한다.
- 추상화 (Abstraction)
- 시스템의 복잡성을 줄이기 위해 중요 속성과 동작만을 추려내어 모델링하고, 세부 사항을 감추어 간결하고 효율적인 설계를 가능하게 한다.
- 다형성 (Polymorphism)
- 동일한 메서드 호출이 객체의 타입에 따라 다르게 동작하도록 하여 코드의 유연성을 높이며, 다양한 객체를 동일한 인터페이스로 다룰 수 있게 한다.
SOLID
객체 지향 설계의 5가지 기본 원칙으로, 코드의 유지보수성과 확장성을 높여준다.
- 단일 책임 원칙 (SRP, Single Responsibility Principle)
- 클래스는 하나의 책임만 가져야 하며, 변경의 이유가 하나여야 한다.
- 개방-폐쇄 원칙 (OCP, Open-Closed Principle)
- 클래스는 확장에는 열려 있어야 하고, 수정에는 닫혀 있어야 한다.
- 리스코프 치환 원칙 (LSP, Liskov Substitution Principle)
- 서브클래스는 언제나 상위 클래스를 대체할 수 있어야 한다.
- 인터페이스 분리 원칙 (ISP, Interface Segregation Principle)
- 인터페이스는 클라이언트에 특화되도록 분리하여 설계해야 한다.
- 의존 역전 원칙 (DIP, Dependency Inversion Principle)
- 고수준 모듈은 저수준 모듈에 의존하지 않고, 추상화에 의존해야 한다.
Design Pattern
소프트웨어 공학에서 자주 발생하는 문제들을 해결하기 위해 재사용 가능한 솔루션을 제공하는 템플릿이다.
생성 패턴
객체 생성과 관련된 패턴으로, 객체 생성 과정을 캡슐화하여 시스템의 유연성과 재사용성을 높인다.
- 싱글턴 패턴 : 클래스의 인스턴스를 단 하나만 생성하고, 전역적으로 접근할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class Singleton {
private static Singleton instance;
private Singleton() {
// 생성자를 private으로 설정하여 외부에서 인스턴스 생성을 방지
}
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
public void showMessage(){
System.out.println("Hello Singleton!");
}
}
- 팩토리 메서드 패턴 : 객체 생성의 인터페이스를 정의하고, 서브클래스가 어떤 클래스의 인스턴스를 생성할지를 결정하게 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// 제품 인터페이스
public interface Product {
void use();
}
// 구체적인 제품 클래스
public class ConcreteProductA implements Product {
public void use() {
System.out.println("Using Product A");
}
}
// 팩토리 클래스
public abstract class Creator {
public abstract Product factoryMethod();
public void someOperation() {
Product product = factoryMethod();
product.use();
}
}
// 구체적인 팩토리 클래스
public class ConcreteCreatorA extends Creator {
public Product factoryMethod() {
return new ConcreteProductA();
}
}
- 추상 팩토리 패턴 : 관련된 객체들을 생성하기 위한 인터페이스를 제공하여, 구체적인 클래스에 의존하지 않도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
// 추상 제품 인터페이스
public interface Button {
void render();
}
public interface Checkbox {
void render();
}
// 구체적인 제품 클래스
public class WinButton implements Button {
public void render() {
System.out.println("Rendering Windows Button");
}
}
public class MacButton implements Button {
public void render() {
System.out.println("Rendering Mac Button");
}
}
public class WinCheckbox implements Checkbox {
public void render() {
System.out.println("Rendering Windows Checkbox");
}
}
public class MacCheckbox implements Checkbox {
public void render() {
System.out.println("Rendering Mac Checkbox");
}
}
// 추상 팩토리
public interface GUIFactory {
Button createButton();
Checkbox createCheckbox();
}
// 구체적인 팩토리
public class WinFactory implements GUIFactory {
public Button createButton() {
return new WinButton();
}
public Checkbox createCheckbox() {
return new WinCheckbox();
}
}
public class MacFactory implements GUIFactory {
public Button createButton() {
return new MacButton();
}
public Checkbox createCheckbox() {
return new MacCheckbox();
}
}
// 클라이언트 코드
public class Application {
private Button button;
private Checkbox checkbox;
public Application(GUIFactory factory) {
button = factory.createButton();
checkbox = factory.createCheckbox();
}
public void render() {
button.render();
checkbox.render();
}
}
구조 패턴
클래스와 객체의 조합을 다루는 패턴으로, 복잡한 구조를 단순화하고 유연성을 향상시킨다.
- 어댑터 패턴 : 호환되지 않는 인터페이스를 가진 클래스를 함께 작동할 수 있도록 변환한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// 기존 클래스
public class Adaptee {
public void specificRequest() {
System.out.println("Specific request");
}
}
// 타겟 인터페이스
public interface Target {
void request();
}
// 어댑터 클래스
public class Adapter implements Target {
private Adaptee adaptee;
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
public void request() {
adaptee.specificRequest();
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
Adaptee adaptee = new Adaptee();
Target target = new Adapter(adaptee);
target.request(); // "Specific request" 출력
}
}
- 데코레이터 패턴 : 객체에 추가적인 기능을 동적으로 추가할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
// 컴포넌트 인터페이스
public interface Coffee {
String getDescription();
double getCost();
}
// 구체적인 컴포넌트
public class SimpleCoffee implements Coffee {
public String getDescription() {
return "Simple Coffee";
}
public double getCost() {
return 2.0;
}
}
// 추상 데코레이터
public abstract class CoffeeDecorator implements Coffee {
protected Coffee decoratedCoffee;
public CoffeeDecorator(Coffee coffee) {
this.decoratedCoffee = coffee;
}
public String getDescription() {
return decoratedCoffee.getDescription();
}
public double getCost() {
return decoratedCoffee.getCost();
}
}
// 구체적인 데코레이터
public class MilkDecorator extends CoffeeDecorator {
public MilkDecorator(Coffee coffee) {
super(coffee);
}
public String getDescription() {
return decoratedCoffee.getDescription() + ", Milk";
}
public double getCost() {
return decoratedCoffee.getCost() + 0.5;
}
}
public class SugarDecorator extends CoffeeDecorator {
public SugarDecorator(Coffee coffee) {
super(coffee);
}
public String getDescription() {
return decoratedCoffee.getDescription() + ", Sugar";
}
public double getCost() {
return decoratedCoffee.getCost() + 0.3;
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
Coffee coffee = new SimpleCoffee();
System.out.println(coffee.getDescription() + " $" + coffee.getCost());
coffee = new MilkDecorator(coffee);
System.out.println(coffee.getDescription() + " $" + coffee.getCost());
coffee = new SugarDecorator(coffee);
System.out.println(coffee.getDescription() + " $" + coffee.getCost());
}
}
- 프록시 패턴 : 실제 객체에 대한 접근을 제어하기 위해 대리 객체를 제공한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
// 서비스 인터페이스
public interface Image {
void display();
}
// 실제 서비스 클래스
public class RealImage implements Image {
private String filename;
public RealImage(String filename) {
this.filename = filename;
loadFromDisk();
}
private void loadFromDisk() {
System.out.println("Loading " + filename);
}
public void display() {
System.out.println("Displaying " + filename);
}
}
// 프록시 클래스
public class ProxyImage implements Image {
private RealImage realImage;
private String filename;
public ProxyImage(String filename) {
this.filename = filename;
}
public void display() {
if(realImage == null) {
realImage = new RealImage(filename);
}
realImage.display();
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
Image image = new ProxyImage("test_image.jpg");
// 이미지가 실제로 로드되는 시점은 display()가 호출될 때
image.display();
image.display();
}
}
행위 패턴
객체 간의 상호작용과 책임 분담을 다루는 패턴으로, 시스템의 동적인 행동을 관리한다.
- 옵저버 패턴 : 객체의 상태 변화가 있을 때, 이를 의존하는 다른 객체들에게 자동으로 알리는 패턴
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
import java.util.ArrayList;
import java.util.List;
// 옵저버 인터페이스
public interface Observer {
void update(String message);
}
// 구체적인 옵저버
public class ConcreteObserver implements Observer {
private String name;
public ConcreteObserver(String name) {
this.name = name;
}
public void update(String message) {
System.out.println(name + " received: " + message);
}
}
// 주제(Subject) 클래스
public class Subject {
private List<Observer> observers = new ArrayList<>();
public void attach(Observer observer){
observers.add(observer);
}
public void detach(Observer observer){
observers.remove(observer);
}
public void notifyObservers(String message){
for(Observer observer : observers){
observer.update(message);
}
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
Subject subject = new Subject();
Observer observer1 = new ConcreteObserver("Observer1");
Observer observer2 = new ConcreteObserver("Observer2");
subject.attach(observer1);
subject.attach(observer2);
subject.notifyObservers("Hello Observers!");
}
}
- 전략 패턴 : 알고리즘을 캡슐화하여, 실행 중에 알고리즘을 교체할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
// 전략 인터페이스
public interface Strategy {
int execute(int a, int b);
}
// 구체적인 전략 클래스
public class AddStrategy implements Strategy {
public int execute(int a, int b) {
return a + b;
}
}
public class SubtractStrategy implements Strategy {
public int execute(int a, int b) {
return a - b;
}
}
public class MultiplyStrategy implements Strategy {
public int execute(int a, int b) {
return a * b;
}
}
// 컨텍스트 클래스
public class Context {
private Strategy strategy;
public void setStrategy(Strategy strategy){
this.strategy = strategy;
}
public int executeStrategy(int a, int b){
return strategy.execute(a, b);
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
Context context = new Context();
// 덧셈 전략 사용
context.setStrategy(new AddStrategy());
System.out.println("10 + 5 = " + context.executeStrategy(10, 5));
// 뺄셈 전략 사용
context.setStrategy(new SubtractStrategy());
System.out.println("10 - 5 = " + context.executeStrategy(10, 5));
// 곱셈 전략 사용
context.setStrategy(new MultiplyStrategy());
System.out.println("10 * 5 = " + context.executeStrategy(10, 5));
}
}
- 템플릿 메서드 패턴 : 알고리즘의 골격을 정의하고, 일부 단계를 서브클래스에서 구현할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// 추상 클래스
public abstract class AbstractClass {
// 템플릿 메서드
public final void templateMethod() {
step1();
step2();
step3();
}
protected void step1() {
System.out.println("Step 1: Common step");
}
protected abstract void step2(); // 서브클래스에서 구현
protected void step3() {
System.out.println("Step 3: Common step");
}
}
// 구체적인 클래스
public class ConcreteClass extends AbstractClass {
protected void step2() {
System.out.println("Step 2: Specific step");
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
AbstractClass instance = new ConcreteClass();
instance.templateMethod();
}
}
- 커맨드 패턴 : 요청을 캡슐화하여, 요청의 발신자와 수신자를 분리하고, 요청을 큐에 저장하거나 로그에 기록할 수 있게 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
// 커맨드 인터페이스
public interface Command {
void execute();
}
// 구체적인 커맨드 클래스
public class LightOnCommand implements Command {
private Light light;
public LightOnCommand(Light light){
this.light = light;
}
public void execute() {
light.on();
}
}
public class LightOffCommand implements Command {
private Light light;
public LightOffCommand(Light light){
this.light = light;
}
public void execute() {
light.off();
}
}
// 수신자 클래스
public class Light {
public void on(){
System.out.println("Light is ON");
}
public void off(){
System.out.println("Light is OFF");
}
}
// 호출자 클래스
public class RemoteControl {
private Command command;
public void setCommand(Command command){
this.command = command;
}
public void pressButton(){
command.execute();
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
Light light = new Light();
Command lightOn = new LightOnCommand(light);
Command lightOff = new LightOffCommand(light);
RemoteControl remote = new RemoteControl();
remote.setCommand(lightOn);
remote.pressButton(); // "Light is ON" 출력
remote.setCommand(lightOff);
remote.pressButton(); // "Light is OFF" 출력
}
}
Clean Code
읽기 쉽고, 이해하기 쉬우며, 유지보수가 용이한 소프트웨어 코드를 작성하는 데 중점을 둔 소프트웨어 개발 철학이다. 클린 코드는 다음과 같은 특징을 갖는다.
- 가독성
- 코드를 읽는 사람이 쉽게 이해할 수 있도록 작성됨.
- 명확성
- 코드의 목적과 기능이 명확하게 드러남.
- 간결성
- 불필요한 복잡성을 제거하고, 필요한 기능만을 포함함.
- 유지보수성
- 코드 변경이나 확장이 용이하도록 구조화됨.
클린 코드의 주요 원칙
의미 있는 이름 사용 : 명확하고 설명적이고 일관되게 이름을 사용함
함수의 단일 책임 원칙 : 함수는 하나의 기능만 수행함
작은 함수 : 짧고 간결함
주석의 사용 : 주석은 필요할 때만 사용, 코드 자체로 충분히 이해될 수 있도록 함
일관된 포맷팅 : 코드 스타일(들여쓰기, 공백, 중괄호 위치)을 일관되게 유지함
예외 처리 : 예외는 로직과 분리하며, 문제의 원인을 명확하게 설명해야 함
DDD (Domain Driven Design)
복잡한 소프트웨어를 효과적으로 관리하고 개발하기 위한 소프트웨어 설계 접근 방식이다. DDD는 소프트웨어의 핵심 비즈니스 로직을 도메인에 집중시키고, 도메인 전문가와 개발자 간의 협력을 강화하여, 유지보수성과 확장성이 높은 소프트웨어를 구축하는 데 중점을 둔다.
TDD (Test Driven Development)
소프트웨어 개발 방법론 중 하나로, 코드를 작성하기 전에 테스트 케이스를 먼저 작성하고, 그 테스트를 통과할 수 있는 최소한의 코드를 구현하는 방식이다. TDD는 소프트웨어의 품질을 향상시키고, 유지보수를 용이하게 하며, 개발 과정을 체계적으로 관리할 수 있도록 도와준다. TDD 개발 프로세스는 다음 순서를 따르는 방법론이다.
- 테스트 작성 (Red) : 아직 구현되지 않은 기능에 대한 테스트 케이스를 작성
- 코드 작성 (Green) : 테스트를 통과할 수 있도록 최소한의 코드 작성
- 리팩토링 (Refactor) : 코드의 구조를 개선하여 가독성을 높이고, 중복을 제거하며, 성능을 향상시킴
Framework & Library
Spring
엔터프라이즈급 애플리케이션 개발을 위한 프레임워크로, 의존성 주입(DI)과 제어의 역전(IoC), 관점 지향 프로그래밍(AOP) 등을 통해 코드의 유연성과 유지보수를 용이하게 한다.
- 의존성 주입 (DI, Dependency Injection)
- 객체 간의 의존성을 외부에서 주입하여 객체 간 결합도를 낮추고, 코드의 유연성과 테스트 용이성을 높이는 설계 패턴이다.
- 제어의 역전 (IoC, Inversion of Control)
- 객체의 생성과 의존성 관리를 프레임워크가 담당하여 코드의 결합도를 낮춘다.
- 관점 지향 프로그래밍 (AOP, Aspect-Oriented Programming)
- 횡단 관심사를 분리하여 핵심 로직과 별도로 관리함으로써 코드 모듈화를 개선하는 프로그래밍 기법이다.
Spring Boot
Spring 애플리케이션 개발을 간소화해주는 프레임워크로, 자동 설정과 내장 서버, 스타터 종속성 등의 기능을 통해 빠르고 간편한 애플리케이션 개발을 지원한다.
Spring WebFlux
Spring WebFlux는 비동기 및 논블로킹 애플리케이션 개발을 지원하는 스프링 프레임워크의 모듈로, 고성능 및 높은 확장성을 요구하는 웹 애플리케이션에 적합하다. 리액티브 프로그래밍 모델을 기반으로 하며, 전통적인 Spring MVC보다 더 효율적으로 리소스 사용과 응답성을 제공한다.
- 논블로킹 리액티브 스트림
- 데이터 스트림을 비동기적으로 처리하며, 백프래셔(backpressure)를 통해 생산자와 소비자 간 데이터 처리 속도를 조절하여 효율적이고 안정적인 데이터 흐름을 보장한다.
- 리액티브 프로그래밍
- 데이터의 흐름과 변화를 비동기적으로 처리하는 프로그래밍 패러다임이다. (ex. Publisher, Subscriber, Flux, Mono)
Armeria
Java 기반 고성능 비동기 및 논블로킹 마이크로서비스 프레임워크로, 다양한 프로토콜(gRPC, HTTP/2, Thrift 등)을 지원하며, 확장성과 유연성을 제공하여 마이크로서비스 아키텍처에 적합하다.
- 장점
- 다양한 프로토콜 지원, 비동기 논블로킹 구조로 고성능, gRPC와 HTTP 간의 네이티브 통합이 뛰어남
- 단점
- 설정이 복잡할 수 있고, 기존 Spring MVC와의 호환성은 제한적
gRPC (Google Remote Procedure Call)
구글이 개발한 오픈 소스 원격 프로시저 호출 프레임워크로, HTTP/2 프로토콜과 프로토콜 버퍼를 사용하여 고성능, 양방향 스트리밍 및 다중 언어 간 통신을 지원한다. 마이크로서비스 간 고성능 통신, 저지연 데이터 전송, 실시간 스트리밍이 필요한 시스템에서 적합하다.
- 장점
- 고성능, HTTP/2 기반 양방향 스트리밍 지원, 프로토콜 버퍼를 통한 효율적 데이터 직렬화, 다중 언어 간 상호 운용성
- 단점
- REST 보다 설정이 복잡하고, 브라우저에서 직접 호출이 어려우며, 디버깅이 까다로울 수 있음
Protobuf (Protocol Buffers)
구글이 개발한 데이터 직렬화 포맷으로, 구조화된 데이터를 빠르고 효율적으로 직렬화하여 다양한 언어와 플랫폼 간 통신을 지원한다.
- 장점
- 빠른 직렬화 속도, 효율적인 데이터 크기, 다중 언어 지원, 구조적 데이터 검증 가능
- 단점
- JSON에 비해 가독성이 낮고, 데이터 스키마가 필요하며, 버전 관리가 복잡할 수 있음
JPA (Java Persistence API)
자바 애플리케이션에서 관계형 데이터베이스와 객체 간 매핑(ORM)을 지원하는 API로, SQL 작성 없이 객체를 데이터베이스 테이블에 매핑하고 CRUD 작업을 수행할 수 있도록 한다. 다음은 JPA의 주요 동작 원리이다.
- EntityManagerFactory 생성
- Persistence.createEntityManagerFactory()를 호출하여 EntityManagerFactory를 생성한다.
- 팩토리는 애플리케이션 전체에서 관리되며, EntityManager 생성을 담당한다.
- EntityManager 생성 및 관리
- EntityManager는 엔티티와 데이터베이스 간의 CRUD 작업을 담당하며, 트랜잭션과 1차 캐시를 관리한다.
- 데이터베이스와의 커넥션 역할을 수행하며, 애플리케이션의 각 트랜잭션 단위로 생성 및 사용된다.
- 트랜잭션 관리
- EntityManager는 트랜잭션을 시작(beginTransaction()), 커밋(commit()), 롤백(rollback()) 할 수 있으며, 데이터 일관성을 보장한다.
- JPA는 엔티티 상태를 자동으로 동기화해 트랜잭션 범위 내에서 데이터베이스와 객체의 변경을 반영한다.
- 1차 캐시와 영속성 컨텍스트
- EntityManager는 1차 캐시 역할을 하며, 한 트랜잭션 동안 동일한 엔티티는 데이터베이스에 다시 조회하지 않고 캐시에서 반환한다.
- JPA는 영속성 컨텍스트를 통해 엔티티 객체의 상태를 관리하고, 트랜잭션 종료 시 데이터베이스와 동기화하여 변경 사항을 반영한다.
- 데이터 변경 감지 (Dirty Checking)
- JPA는 영속 상태의 엔티티에서 변경된 값을 자동으로 감지하여 트랜잭션 종료 시 변경된 데이터를 데이터베이스에 반영한다.
- 데이터 변경 감지 메커니즘을 통해 엔티티가 수정되면, flush() 메서드를 호출해 트랜잭션 종료 시 데이터베이스와 자동으로 동기화한다.
- 지연 로딩 (Lazy Loading)
- JPA는 연관 관계를 가진 엔티티를 필요할 때 로드하는 지연 로딩을 지원하여 성능 최적화를 돕는다. 지연 로딩이 설정된 엔티티는 실제로 접근할 때 로드된다.
- 2차 캐시
- 애플리케이션 전역에서 사용 가능한 캐시로, 여러 EntityManager 또는 세션 간에 공유된다.
- 애플리케이션 전체에서 유효하며, 한 번 로드된 엔티티는 애플리케이션 범위에서 재사용 가능하다.
- 데이터베이스와의 접근을 줄여 성능을 항상시킬 수 있다.
Hibernate
JPA 구현체 중 하나로, 자바 객체와 데이터베이스 간 매핑을 자동으로 처리하는 ORM 프레임워크이다. 복잡한 SQL 쿼리를 작성할 필요 없이 객체지향적으로 데이터베이스 작업을 수행할 수 있도록 하며, 캐싱, 연관 관계 매핑, 지연 로딩 등의 기능을 제공한다.
R2DBC (Reactive Relational Database Connectivity)
리액티브 스트림(Reactive Streams) 사양을 기반으로 하는 비동기 관계형 데이터베이스 연결을 위한 표준 API이다. 기존의 블로킹 방식인 JDBC와 달리 R2DBC는 비동기 스트링 방식으로 데이터를 처리하여 높은 성능과 확장성을 제공한다. R2DBC는 Spring WebFlux와 같은 리액티브 프레임워크와 함께 사용하기 적합하다.
- 장점
- 동시성을 높이고, 많은 요청을 효율적으로 처리 가능하다. 쿼리 결과를 스트리밍 방식으로 처리하여 메모리 효율성을 향상시킨다.
- 단점
- 성숙도가 낮아 드라이버 지원이 제한적이다. 학습 곡선이 있으며 동기 코드와 혼합 사용이 어렵다. 트랜잭션 관리가 복잡할 수 있으며, 블로킹 방식보다 디버깅이 어렵다.
R2DBC vs JDBC
| 특징 | R2DBC | JDBC |
|---|---|---|
| I/O 방식 | 비동기, 논블로킹 | 동기식, 블로킹 |
| 프로그램 모델 | 리액티브 스트림스 (Flux, Mono 등) | 전통적인 객체지향 모델 |
| 성능 | 높은 동시성 및 확장성 | 상대적으로 낮은 동시성, 스레드 의존적 |
| 리소스 사용 | 효율적인 리소스 사용 (스레드 절약) | 많은 스레드 필요, 리소스 소비 많음 |
| 트랜잭션 관리 | 리액티브 트랜잭션 관리 복잡 | 전통적인 트랜잭션 관리 (간단) |
| 성숙도 | 비교적 새로운 사양, 드라이버 성숙도 낮음 | 오래된 사양, 높은 드라이버 성숙도 및 호환성 |
| 커뮤니티 지원 | 성장 중인 커뮤니티, 자료 및 예제 제한적 | 광범위한 커뮤니티 지원, 풍부한 자료 및 예제 |
| 사용 사례 | 고성능, 마이크로서비스, 실시간 데이터 처리 | 전통적인 웹 애플리케이션, 단일 서버 애플리케이션 |
MyBatis
자바 객체와 SQL 데이터베이스 간의 매핑을 지원하는 퍼시스턴스 프레임워크로, SQL 쿼리를 XML이나 애노테이션으로 관리하며 복잡한 쿼리를 간편하게 실행할 수 있도록 돕는다.13
Security
OAuth (Open Authorization)
사용자가 비밀번호를 제공하지 않고도 다른 웹사이트나 애플리케이션에 자신의 정보에 대한 접근 권한을 부여할 수 있는 개방형 표준 프로토콜이다.14
JWT (JSON Web Token)
두 시스템 간 정보를 안전하게 전송하기 위한 개방형 표준으로, 주로 사용자 인증과 권한 부여에 사용된다.15
Infra
Message Queue
비동기 통신을 위해 메시지를 대기열에 저장하고 순차적으로 처리하는 시스템으로, 시스템 간 데이터 전달과 작업 분산을 효율적으로 관리한다. 대규모 트래픽 처리, 비동기 작업(ex. 이메일 발송), 마이크로서비스 간 통신, 주문 처리 시스템 등 신뢰성 있고 비동기 데이터 처리가 필요한 곳에 적합하다. 대표적인 예시로 RabbitMQ와 Kafka가 있다.
- 장점
- 시스템 간 비동기 통신 지원으로 성능과 확장성 향상, 메시지 저장으로 데이터 유실 방지, 작업 분산 가능
- 단점
- 설정과 관리가 복잡할 수 있으며, 메시지 지연이나 큐 과부화 상황 발생 가능
RabbitMQ
AMQP 프로토콜을 기반으로 하는 오픈 소스 메시지 브로커로, 메시지 큐를 통해 시스템 간 비동기 통신을 지원하며, 신뢰성과 확장성이 뛰어난 메시지 전송을 제공한다.
- 장점
- AMQP 지원으로 신뢰성 높은 메시지 전송, 다양한 메시지 라우팅 방식, 높은 확장성과 다중 언어 클라이언트 지원
- 단점
- 높은 메시지 처리 속도에서는 Kafka 보다 성능이 떨어질 수 있음
AMQP (Advanced Message Queuing Protocol)
메시지 지향 미들웨어에서 상호 운용성과 신뢰성 높은 메시지 전달을 보장하는 프로토콜로, 큐잉, 라우팅, 메시지 보안 등을 표준화하여 다양한 시스템 간 원활한 통신을 지원한다.
동작 방식은 다음과 같다.
- 프로듀서가 메시지를 생성하고 익스체인지(Exchange)에 전송
- 익스체인지는 메시지를 라우팅 키(Routing Key)에 따라 적절한 큐에 분배. 다이렉트, 팬아웃, 토픽 등의 방식으로 메시지를 라우팅
- 다이렉트 : 라우팅 키와 일치하는 큐에만 전달
- 팬아웃 : 모든 바인딩된 큐에 메시지를 브로드캐스트
- 토픽 : 라우팅 키의 패턴을 기반으로 메시지를 큐에 전달
- 큐(Queue)에 메시지가 저장되고, 컨슈머가 이를 대기열에서 가져와 처리
- 큐에서 메시지를 처리한 컨슈머는 ACK(확인 응답)을 브로커에 보내 성공적으로 처리되었음을 알림
Kafka
아파치 재단에서 개발한 분산 스트리밍 플랫폼으로, 대용량 실시간 데이터 스트리밍과 처리에 적합하며, 메시지 큐와 로그 저장 시스템을 결합해 높은 처리량과 내구성을 제공한다.
- 장점
- 높은 처리량과 내구성, 대규모 실시간 데이터 스트리밍 지원, 분산 아키텍처로 확장성 뛰어남
- 단점
- 설정과 운영 복잡, 메시지 순서 보장 어려울 수 있으며, 초기에 리소스 요구가 큼
RabbitMQ와 Kafka 선택 기준
RabbitMQ는 신뢰성 있는 메시지 전송과 다양한 라우팅이 필요할 때 적합하고, Kafka는 대규모 데이터 스트리밍과 높은 처리량이 필요한 실시간 로그 및 이벤트 처리에 적합하다.
Docker
애플리케이션과 의존성을 컨테이너라는 가벼운 환경에 패키징하여, 일관된 실행 환경을 제공하는 오픈 소스 플랫폼이다. 이를 통해 애플리케이션을 신속하게 배포하고, 환경 간 호환성을 보장하며 리소스 효율성을 높인다.
Kubernates
컨테이너화된 애플리케이션의 배포, 확장, 관리 자동화를 위한 오픈 소스 플랫폼으로, 다양한 환경(온프레미스, 클라우드 등)에서 컨테이너 오케스트레이션을 지원하며, 서비스 복구, 로드 밸런싱, 자동 확장 등의 기능을 제공한다.
Helm
Kubernates 애플리케이션을 관리하기 위한 패키지 매니저로, 애플리케이션을 차트(chart)라는 패키지로 정의하고 배포, 업그레이드, 롤백 등을 쉽게 수행할 수 있도록 한다. 이를 통해 Kubernates 리소스의 복잡한 설정을 간소화하고 일관성 있는 배포 환경을 제공한다.
AWS
EKS (Amazon Elastic Kubernates Service)
AWS에서 제공하는 Kubernetes 관리 서비스로, Kubernetes 클러스터를 손쉽게 설정, 운영 및 확장할 수 있도록 지원하며, 자동화된 클러스터 관리와 AWS 인프라 통합을 통해 고가용성과 보안을 제공한다.
Zipkin
분산 트레이싱 시스템으로, 마이크로서비스 아키텍처에서 요청이 여러 서비스에 걸쳐 처리될 때 각 서비스 간의 호출 관계와 성능 병목을 추적한다. 이를 통해 서비스 간 요청의 흐름을 시각화하고 지연 시간 문제를 식별하며, 트랜잭션 경로의 병목 지점을 분석하여 성능 최적화에 도움을 준다.
Grafana
다양한 데이터 소스(MySQL, Prometheus 등)에서 수집된 메트릭 데이터를 시각화하고 모니터링하는 오픈 소스 분석 및 대시보드 도구로, 실시간 모니터링과 경고 설정이 가능하다.16
OS
프로세스
운영체제에서 실행 중인 프로그램의 인스턴스로, 독립적인 메모리 공간을 할당받아 자체적으로 자원과 상태를 관리한다.
스레드
프로세스 내에서 실행되는 작은 실행 단위로, 같은 메모리 공간을 공유하며 프로세스 자원 내에서 병렬 처리가 가능하다.
동기 (Synchronous)
요청 후 응답이 완료될 때까지 기다리며 순차적으로 작업을 처리하는 방식이다.
- 장점
- 코드 흐름이 직관적이며 디버깅이 용이함
- 단점
- 요청이 완료될 때까지 대기해야 하므로 성능과 확장성이 제한될 수 있음
비동기 (Asynchronous)
요청 후 응답을 기다리지 않고 다른 작업을 수행하며 나중에 결과를 처리하는 방식이다. 웹 서버 요청 처리, 파일 I/O, 데이터베이스 쿼리, 알림 시스템 등 응답 시간이 긴 작업에서 주로 사용된다.
- 장점
- 높은 성능과 확장성으로 많은 작업을 동시에 처리 가능
- 단점
- 코드 복잡성이 증가하고, 디버깅과 예외 처리가 어려울 수 있음
블로킹 (Blocking)
작업이 완료될 때까지 해당 작업을 실행 중인 스레드가 다른 작업을 수행하지 못하고 대기하는 방식이다.
- 장점
- 구현이 간단하고 이해하기 쉬우며, 직관적인 흐름 제공
- 단점
- 리소스가 대기 상태로 묶여 성능 저하와 확장성 한계가 발생할 수 있음
논블로킹 (Non-blocking)
작업이 완료될 때까지 기다리지 않고, 스레드가 즉시 다른 작업을 계속 수행할 수 있는 방식이다. 대규모 트래픽을 처리하는 웹 서버, 실시간 애플리케이션, 데이터 스트리밍 등에서 성능과 확장성이 중요한 곳에 적합하다.
- 장점
- 리소스를 효율적으로 사용해 성능과 확장성 향상 가능
- 단점
- 코드가 복잡해지고, 예외 처리와 디버깅이 어려울 수 있음